
빙응의 공부 블로그
[OSTEP 가상화(virtualization)]세그멘테이션 본문

📝서론 : 베이스와 바운드 방식의 단점
전 시간에는 베이스와 바운드 방식을 배웠습니다. 하지만 이 방식에도 단점이 존재합니다.
바로 비효율적인 메모리 사용에 있습니다. 아래 그림처럼 전통적인 주소 공간은 힙이 아래쪽으로 스택은 위쪽으로 자랍니다. 이 둘이 충돌하지 않도록 충분한 여유 공간을 남겨둡니다. 여기에서 문제가 발생합니다.
- 베이스와 바운드 방식은 프로세스의 전체 주소 공간을 물리 메모리에 통째로 적재하기에 힙과 스택 사이의 미사용 공간까지 물리 메모리를 차지하게 됩니다.
- 주소 공간이 물리 메모리보다 큰 경우 실행이 어렵다는 단점이 있습니다.

📝19.1 세그멘테이션 : 베이스/바운드의 일반화
앞서 베이스와 바운드 레지스터는 하나로 프로세스 전체 주소 공간을 통제했습니다.
이곳에서 스택과 힙 사이 미사용 공간 낭비, 가상 주소 공간이 커질 경우 실행 불가, 메모리 재배치의 어려움 이 3가지 문제가 발생했다. 이것을 해결하기 위한 아이디어가 바로 세그멘테이션입니다.
💡 핵심 아이디어: 주소 공간을 나눠서 관리하자!
"주소 공간을 코드, 스택, 힙 같은 논리적 단위(세그먼트)로 나누고 각각에 베이스/바운드 레지스터를 따로 두자"
예를 들어 이렇게 나눌 수 있다.
| 세그먼트 | 베이스(물리주소) | 바운드(크기) |
| 0 (코드) | 1000 | 500 |
| 1 (스택) | 2000 | 300 |
| 2 (힙) | 3000 | 700 |
여담 : 세그먼트 폴트
세그먼트 폴트는 세그먼트 사용 시스템에서 불법적인 주소 접근 시 발생한다.
📝19.2 세그먼트 종류의 파악
하드웨어는 변환을 위해 세그먼트 레지스터를 사용한다. 하드웨어는 가상 주소가 어느 세그먼트를 참조하는지 그리고 그 세그먼트 안에서 오프셋은 얼마인지 어떻게 알 수 있을까?
첫번째 : 일반적인 접근법
가상 주소의 최상위 몇 비트를 기준으로 주소 공간을 여러 세그먼트로 나누는 것이다.
위의 예에서는 3개의 세그먼트가 있습니다. 주소 공간을 세그먼트로 나누기 위해서는 2비트가 필요하다.
그 예로 세그먼트를 표시하기 위해선 가상 주소 14비트 중 최상위 2비트를 사용하는 경우 가상 주소의 모양은 다음과 같다.
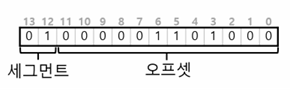
위의 그림을 해석해보면 최상위 2비트는 01로 스택 세그먼트를 나타냅니다.
그리고 오프셋 즉 저장되어 있는 위치를 표시하는 수는 10진수로 104번에 위치합니다 이것을 베이스와 더하면 원하는 주소에 접근이 가능합니다.
- 세그먼트 01 : 스택 세그먼트 (Base 2000)
- 오프셋 104 : 번호 Base 2000 + 104 = 최종 물리 주소 2104번에 위치
두번째 : 묵시적 접근법
해당 방법은 주소가 어떻게 형성되었나를 관찰하여 세그먼트를 결정합니다.. 예를 들어, 주소가 프로그램 카운터(PC)에 생성되었다면 주소는 코드 세그먼트 내에 있을 것입니다.
주소가 스택 도는 베이스 포인터에 기반을 둔다면 주소는 스택 세그먼트 내에 있는 것이다.
📝19.3 스택
지금까지 주소 공간의 중요한 구성 요소인 스택을 다루지 않았습니다.
스택 세그먼트는 다른 세그먼트와 큰 차이가 있습니다. 바로 반대 방향으로 확장된다는 것입니다.
그렇기에 다른 방식으로 변환이 필요합니다.
첫번째 : 간단한 하드웨어 추가
베이스와 바운드 값뿐 아니라 하드웨어는 세그먼트가 어느 방향으로 확장하는지도 알아야합니다.
예를 들어, 하나의 비트를 사용하여 주소가 커지는 쪽(양 방향)으로 확장하면 스택은 작아지는 쪽으로 확장해야한다.
하드웨어는 세그먼트가 반대 방향으로 늘어나는 것을 알고 있기에 힙, 코드와 다른 방식으로 변환합니다.
| 세그먼트 | 베이스 | 사이즈 | 방향 |
| Code | 32 KB | 2 KB | 1 |
| Heap | 34 KB | 3 KB | 1 |
| Stack | 28 KB | 2 KB | 0 |
가상 주소 -> 물리 주소 변환 예시
11 1100 0000 0000
위의 예시 비트를 찾아봅시다. 14비트로 표현 시 상위 2비트는 세그먼트 식별에 사용합니다.
여기서 11은 스택 세그먼트를 의미합니다.
하위 12비트는 오프셋으로 변환 시 3KB(3072 bytes)가 나옵니다.
스택 세그먼트는 뱡향이 0으로 음수 오프셋을 계산합니다.
- 최대 세그먼트 크기 : 오프셋 비트로 표현가능한 최대인 4096 bytes(4 KB)
- 음수 오프셋 = 오프셋 - 최대 세그먼트 크기 = 3 KB - 4 KB = -1 KB
- 물리 주소 계산 = 베이스(28 KB) + (-1 KB) = 27 KB
바운드 검사는 음수 오프셋의 절대값이 현재 세그먼트 크기 인지를 확인합니다.
📝19.4 공유 지원
세그먼테이션 기법이 발전함에 따라 시스템 설계자들은 간단한 하드웨어 지원으로 새로운 종류의 효율성을 얻을 수 있다는 것을 깨달았습니다.
구체적으로는 메모리를 절약하기 위해 때로는 주소 공간들 간에 특정 메모리 세그먼트를 공유하는 것이 유용하다는 것을 알았습니다. 특히 코드 공유가 일반적이며, 현재 시스템에서도 광범위하게 사용 중입니다.(코드 세그먼트는 시스템 라이브러리 같은 것을 중복으로 넣을 이유가 없기에 공유가 일반적이다.)
공유를 위해서는 하드웨어는 보안을 위한 것이 필요합니다. 만약 공유 중 주인 프로세스가 아닌 다른 프로세스가 해당 자원을 변경 및 추가를 한다면 문제가 될 수 있기에 Protection bit라는 보호 비트를 추가했습니다.
해당 보호 비트 추가하면 하드웨어 알고리즘을 수정해야 합니다. 각 세그먼트가 읽기, 쓰기, 실행에 대한 액서스 허용이 되는지 확인해야하는 과정을 거쳐야 하기 때문입니다.

📝19.5 소단위 대 대단위 세그먼테이션
우리 예제의 대부분은 지금까지 소수의 세그먼트를 지원하는 시스템으로 소개했다.
우리는 이 세그먼테이션을 대단위라고 하며 비교적 큰 단위의 공간을 분할한다. 일부 초기 시스템은 작은 크기의 공간으로 잘게 나누는 것을 하는 소단위 세그먼테이션을 하기도 하였다.
많은 수의 세그먼트를 지원하기 위해서는 여러 세그먼트의 정보를 메모리에 저장할 수 있는 테이블이 필요했다.
세그먼트 테이블을 이용하면 매우 많은 세그먼트를 아주 쉽게 사용할 수 있다.
이렇게 보면 정말 좋아보이지만 3가지 큰 단점이 존재한다.
- 복잡성과 오버헤드 증가 : 세그먼트마다 관리 정보가 필요하며 하드웨어 복잡도 증가
- 외부 단편화 문제 : 세그먼테이션은 고정 크기 단위가 아니기에 외부 단편화 유발
- 페이징이 더 실용적
📝19.6 외부 단편화
세그먼테이션은 실행 시 외부 단편화라는 문제가 발생한다. 외부 단편화란 세그먼트가 가변 크기이기에 발생하는 빈 메모리 공간들을 말하는 것이다.
외부 단편화는 다음과 같은 상황에서 발생한다.
- 메모리 할당, 해제 반복
- 프로세스가 크기가 다른 세그먼트를 여러 번 요청하면서 빈 공간 발생
- 여러 개의 작은 빈 공간 조각
- 해제된 자리들이 흩어져서 각각 작은 조각이 남음
- 연속된 큰 공간 부족
- 총 빈 공간은 충분하지만, 원하는 크기를 한 번에 담을 구역이 없음
메모리 압축
메모리의 모든 사용 중인 세그먼트를 모아서 한쪽으로 붙이고 빈 공간을 모으는 과정이다.
목적은 분산된 작은 공간을 모아 큰 블록으로 만드는 외부 단편화 극복이다.
물론 이론적으로 정말 좋으나 큰 단점이 있다.
바로 해당 작업이 매우 높은 비용이라는 것과 운영체제 자체의 복잡도가 증가하며 압축 시에 다른 작업을 멈춰야 한다.
빈 공간 관리 알고리즘
해당 방식은 외부 단편화를 어느정도 막으며 경제적인 방식으로 해결하는 것이다.
즉 완전히 막진 못하지만 예방만 하자는 것이다. 그리고 메모리 압축보다 압도적으로 저렴하다.
| 기법 | 설명 | 장점 | 단점 |
| 최초 적합 | 리스트 처음부터 탐색해 크기 ≥ 요청 크기인 곳에 할당 | 빠름(탐색 짧음) | 작은 조각을 먼저 사용→더 많은 단편화 |
| 최적 적합 | 요청 크기와 가장 비슷한(가장 작은 과잉) 공간 선택 | 남는 조각 최소화 | 리스트 전체 탐색으로 느림 |
| 최악 적합 | 가장 큰 빈 공간에 할당 | 큰 빈 공간을 유지해 대형 요청 대응 | 단편화 심화 가능 |
| 버디 시스템 | 2^k 크기의 블록으로 관리, 요청 맞춰 반씩 분할 | 블록 합치기 쉬움(병합·분할) | 내부 단편화(internal fragmentation) 발생 |
📝19.7 세그먼테이션의 단점
세그먼테이션은 많은 문제를 해결하며, 메모리 가상화를 효과적으로 실현했다.
그러나 살펴본 것처럼 세그먼트의 크기가 일정하지 않기 때문에 몇 가지 문제가 발생한다.
외부 단편화 문제
외부 단편화는 세그먼트가 가변 크기이기에 발생한다.
세그먼트가 가변이기에 빈 공간들이 가변 크기로 발생하여 메모리 할당이 어려워지게 된다. 그렇기에 메모리 낭비가 발생하는 것이다. 비교적 정교한 알고리즘을 사용하거나 주기적으로 메모리 압축이 가능하지만 태생적으로 회피는 어렵다.
유연성 문제
세그먼테이션은 아직 일반적인 드문드문 사용되는 주소 공간을 지원할 만큼 충분히 유연하지 않다.
예를 들어, 크기가 크지만 드문드문 사용되는 힙이 하나의 논리적인 세그먼트에 배정되어 있다고 하면 이 힙에 접근을 위해 힙 전체가 여전히 물리 메모리에 존재해야 한다. 다시 말해서 주소 공간이 사용되는 모델과 이를 지원하는 세그먼테이션의 설계 방법이 정확히 일치하지 않는다면 동작하지 않는다.
스포를 하자면 이러한 문제점을 완화하기 위해 페이징을 활용한다.
📝정리
📌 세그멘테이션 요약 정리
1. 베이스/바운드 방식의 한계
- 전체 주소 공간을 통째로 메모리에 올려야 하므로 비효율적인 메모리 사용 발생.
- 힙과 스택 사이의 미사용 공간까지 차지.
- 주소 공간이 크면 실행 불가.
2. 세그멘테이션 도입
- 주소 공간을 코드, 스택, 힙 등 논리 단위(세그먼트)로 나눠 관리.
- 각 세그먼트마다 베이스/바운드 레지스터 따로 사용 → 메모리 낭비 줄임.
3. 가상 주소 변환
- 가상 주소는 세그먼트 번호 + 오프셋으로 구성.
- 오프셋은 베이스와 더해 실제 물리 주소 계산.
- 스택은 반대 방향(감소)으로 확장되므로 별도 처리 필요.
4. 공유 및 보호
- 코드 세그먼트 공유 가능 (라이브러리 등).
- 보호 비트(Protection bit)로 접근 권한(읽기/쓰기/실행) 제어.
5. 세그먼트 수 확장
- 많은 세그먼트를 위해 세그먼트 테이블 사용.
- 그러나 하드웨어 복잡도, 외부 단편화 문제 존재.
6. 외부 단편화 문제
- 메모리 사용 중 빈 공간이 조각남.
- 메모리 압축으로 해결 가능하나, 비용 큼.
- 최초 적합, 최적 적합, 버디 시스템 등으로 완화 가능.
7. 세그멘테이션의 한계
- 외부 단편화 발생 → 메모리 낭비.
- 드문드문 사용되는 주소 공간에 비효율적.
- ➡️ 다음 해결책: 페이징(Paging) 도입 예정.
'CS > 운영체제' 카테고리의 다른 글
| [OSTEP 가상화(virtualization)]페이징: 개요 (0) | 2025.04.24 |
|---|---|
| [OSTEP 가상화(virtualization)]빈 공간 메모리 관리 (0) | 2025.04.24 |
| [OSTEP 가상화(virtualization)]메모리 가상화 (0) | 2025.01.10 |
| [OSTEP 가상화(virtualization)]Chapter 10 멀티프로세서 스케줄링 (0) | 2025.01.09 |
| [OSTEP 가상화(virtualization)]Chapter 9 비례 배분 (0) | 2025.01.09 |



