
빙응의 공부 블로그
[+/KM]공간 데이터 데이터베이스 최적화를 위한 MongoDB 도입 본문

📝배경
[개인프로젝트]공간 데이터 최적화하기
📝배경 이번에 개인 프로젝트를 진행하면서 공공데이터 포탈의 의료 데이터를 사용하게 되었습니다.그래서 의료 데이터 중 병원, 약국의 정보를 저장하여 그 데이터 중에서 좌표를 활용해서
quddnd.tistory.com
해당 포스팅에서 저는 공간 데이터를 이용한 병원, 약국 정보 조회에 대해 최적화를 진행했습니다.
이번에는 공간 데이터, 함수, 관계 함수를 제외한 나머지 요소들로 최적화를 진행하기로 했습니다.
해당 사항에 대한 리팩토링 과정을 정리하겠습니다.
📝MySQL 공간 인덱스
MySQL의 공간 인덱스는 R-Tree 인덱스라고 부릅니다. 그 이유 Rectangle의 R과 B-Tree 인덱스를 합쳤기 때문입니다.
R-Tree 인덱스는 구성 요소를 MBR 기준으로 저장하며 B-Tree의 구조를 따릅니다.
R-Tree는 다차원 공간 데이터를 효율적으로 저장하고 검색하기 위해 설계된 트리 기반 데이터 구조입니다. 특히, 지리 정보 시스템(GIS), 공간 데이터베이스, 지도 서비스 등에서 사용되며, 객체 간의 범위와 위치를 기반으로 쿼리를 최적화하는 데 적합합니다.
그렇기에 MySQL에서 공간 데이터를 취급할 때 필수라고 할 수 있습니다.
일단 그러면 MySQL에서 공간 인덱스를 제외했을 때 어떤 차이를 보이는지 확인해보겠습니다.
explain analyze
SELECT *
FROM place
WHERE ST_Within(coordinate,
ST_GeomFromText('POLYGON((37.5396 126.9511, 37.5934 126.9511, 37.5934 127.0049, 37.5396 127.0049, 37.5396 126.9511))', 4326));해당 쿼리로 진행할 예정이며 전국 병원, 약국의 합산 숫자인 약 10만 건으로 진행할 것입니다.
📌공간 인덱스 없이 조회
10KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((37.4765 126.8880,
37.6565 126.8880, 37.6565 127.0680, 37.4765 127.0680, 37.4765 126.8880))\',4326))) (cost=10101
rows=98359) (actual time=0.292..6775 rows=15221 loops=1)\n
-> Table scan on place (cost=10101 rows=98359) (actual time=0.0609..284 rows=100676 loops=1)\n'해당 쿼리 결과로 15221개의 결과가 반환되었으며 6775ms가 걸렸습니다.
50KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((37.1165 126.5280,
38.0165 126.5280, 38.0165 127.4280, 37.1165 127.4280, 37.1165 126.5280))\',4326))) (cost=10101
rows=98359) (actual time=0.239..7603 rows=49367 loops=1)\n
-> Table scan on place (cost=10101 rows=98359) (actual time=0.0425..273 rows=100676 loops=1)\n'해당 쿼리 결과로 49367개의 결과가 반환되었으며 7603ms가 걸렸습니다.
100KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((36.6665 126.0780,
38.4665 126.0780, 38.4665 127.8780, 36.6665 127.8780, 36.6665 126.0780))\',4326))) (cost=10101
rows=98359) (actual time=0.169..7785 rows=55381 loops=1)\n
-> Table scan on place (cost=10101 rows=98359) (actual time=0.0341..270 rows=100676 loops=1)\n'해당 쿼리 결과로 55381개의 결과가 반환되었으며 7785ms가 걸렸습니다.
ALL
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((33.0 124.6, 38.6 124.6
, 38.6 131.9, 33.0 131.9, 33.0 124.6))\',4326))) (cost=10101 rows=98359)
(actual time=0.222..7905 rows=100676 loops=1)\n
-> Table scan on place (cost=10101 rows=98359) (actual time=0.0521..253 rows=100676 loops=1)\n'해당 쿼리 결과로 100676개의 결과가 반환되었으며 7905ms가 걸렸습니다.
이 실험의 결과에서 이상한 점은 ALL과 100KM가 비슷하다는 것인데 그 이유는 중점이 되는 좌표가 서울 중구로 공간 데이터 분포상 서울에 병원, 약국이 밀집되어있기 때문입니다.
| 10KM | 50KM | 100KM | ALL |
| 15211건 | 49367건 | 55381건 | 100676건 |
| 6775ms | 7603ms | 7785ms | 7905ms |
이렇게보면 차이가 크지 않는 것처럼 보입니다. 그 이유는 인덱스를 사용하지 않아 전체 테이블 풀 스캔을 통해서 조회를 하기 때문에 일정 조회 이상부터는 크게 차이가 나지 않습니다.
📌공간 인덱스 조회
10KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((37.4765 126.8880,
37.6565 126.8880, 37.6565 127.0680, 37.4765 127.0680, 37.4765 126.8880))\',4326))) (cost=49.8
rows=110) (actual time=0.369..1132 rows=15221 loops=1)\n
-> Index range scan on place using coordinate over (coordinate unprintable_geometry_value) (cost=49.8 rows=110) (actual time=0.272..131 rows=15228 loops=1)\n'해당 쿼리 결과로 15221개의 결과가 반환되었으며 1132ms가 걸렸습니다.
50KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((37.1165 126.5280,
38.0165 126.5280, 38.0165 127.4280, 37.1165 127.4280, 37.1165 126.5280))\',4326))) (cost=1240
rows=2756) (actual time=0.401..3758 rows=49367 loops=1)\n
-> Index range scan on place using coordinate over (coordinate unprintable_geometry_value) (cost=1240 rows=2756) (actual time=0.304..434 rows=49370 loops=1)\n'
해당 쿼리 결과로 49367개의 결과가 반환되었으며 3758ms가 걸렸습니다.
100KM
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((36.6665 126.0780,
38.4665 126.0780, 38.4665 127.8780, 36.6665 127.8780, 36.6665 126.0780))\',4326))) (cost=4966
rows=11034) (actual time=0.544..4367 rows=55381 loops=1)\n
-> Index range scan on place using coordinate over (coordinate unprintable_geometry_value) (cost=4966 rows=11034) (actual time=0.417..505 rows=55445 loops=1)\n'해당 쿼리 결과로 55381개의 결과가 반환되었으며 4367ms가 걸렸습니다.
ALL
'-> Filter: st_within(place.coordinate,<cache>(st_geomfromtext(\'POLYGON((33.0 124.6,
38.6 124.6, 38.6 131.9, 33.0 131.9, 33.0 124.6))\',4326))) (cost=10101 rows=98359)
(actual time=0.119..6052 rows=100676 loops=1)\n
-> Table scan on place (cost=10101 rows=98359) (actual time=0.0243..261 rows=100676 loops=1)\n'해당 쿼리 결과로 100676개의 결과가 반환되었으며 6052ms가 걸렸습니다.
둘다 정리하면 다음과 같습니다.

사실 마지막 ALL은 거의 성능이 비슷합니다. 그 이유는 MySQL 옵티마이저에서 데이터 탐색 비율에 따라 인덱스 대신 풀 테이블 스캔을 사용하기 때문입니다. 그 이유는 인덱스의 랜덤 I/O보다 테이블의 순차 I/O가 데이터 탐색 비율이 높으면 훨씬 유리하기 때문입니다.
저의 서비스는 전체 검색 또한 지원합니다. 그렇기에 전체 검색을 사용해야하며 중요한 것은 전체 검색은 인덱스를 사용해도 최적화가 불가능한 것입니다.
그래서 더 유연하게 공간 데이터 최적화를 위해 MongoDB를 도입해보겠습니다.
📝MongoDB 도입하기
MongoDB는 NoSQL 데이터베이스로, 2D 및 GeoJSON 형식의 공간 데이터를 저장하고 지리적 쿼리를 지원합니다.
조회에 특화된 데이터베이스이지만 단점으로는 관계형 데이터베이스에서 비해 복잡한 쿼리나 조인에 취약합니다.
하지만 저의 프로젝트는 데이터가 크게 많지 않기 때문에(10만건) MySQL을 통해 관계형 데이터베이스를 구현하고 MongoDB로 병원/약국 조회를 구현하겠습니다.
이렇게 할 수 있는 이유는 병원/약국 테이블은 CSV파일이 최신화될 때를 제외하고는 변경점이 없기 때문입니다.
그렇기에 MySQL로 중복처리, 최신화를 진행하고 MongoDB에 카피하면 됩니다.
@Order(2)
@DummyDataInit
public class PlaceMongoInitializer implements ApplicationRunner {
private final MongoTemplate mongoTemplate;
private final PlaceRepository placeRepository;
@Override
public void run(ApplicationArguments args) throws Exception {
mongoTemplate.dropCollection(MongoPlace.class); // 기존 데이터 삭제
placeRepository.findAll().forEach(place -> { // Place 데이터를 MongoPlace로 변환하여 저장
MongoPlace mongoPlace = MongoPlace.builder()
.id(place.getId().toString())
.name(place.getName())
.placeType(place.getPlace_type().name())
.address(place.getAddress())
.tel(place.getTel())
.coordinate(new GeoJsonPoint(place.getCoordinate().getX(), place.getCoordinate().getY()))
.build();
mongoTemplate.save(mongoPlace);
});
}
}일단 MySQL에서 MongoDB로 카피하는 것을 만들었습니다.
Order를 이용해서 처음은 MySQL에 작업을 한 후 MongoDB로 이식하는 것으로 구현했습니다.
@Document(collection = "place")
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Getter
public class MongoPlace {
@Id
private String id;
private String name;
private String placeType;
private String address;
private String tel;
@GeoSpatialIndexed(type = GeoSpatialIndexType.GEO_2DSPHERE) // 좌표에 대한 인덱스를 생성
private GeoJsonPoint coordinate;
}MySQL의 Entity인 Document를 구현했습니다. 구성 자체는 같습니다.
아래는 실험할 쿼리이며 MySQL과 동일합니다.
db.place.find({
coordinate: {
$geoWithin: {
$geometry: {
type: "Polygon",
coordinates: [
[
[126.8880, 37.4765],
[127.0680, 37.4765],
[127.0680, 37.6565],
[126.8880, 37.6565],
[126.8880, 37.4765]
]
]
}
}
}
}).explain("executionStats");
10KM
executionSuccess: true,
nReturned: 15221,
executionTimeMillis: 162,
totalKeysExamined: 18527,
totalDocsExamined: 18505,해당 쿼리 결과로 15221개의 결과가 반환되었으며 162ms가 걸렸습니다.
50KM
executionSuccess: true,
nReturned: 49367,
executionTimeMillis: 344,
totalKeysExamined: 51422,
totalDocsExamined: 51402,
해당 쿼리 결과로 49367개의 결과가 반환되었으며 344ms가 걸렸습니다.
100KM
executionSuccess: true,
nReturned: 55381,
executionTimeMillis: 362,
totalKeysExamined: 57717,
totalDocsExamined: 57699,해당 쿼리 결과로 55381개의 결과가 반환되었으며 362ms가 걸렸습니다.
ALL
executionSuccess: true,
nReturned: 100676,
executionTimeMillis: 945,
totalKeysExamined: 100676,
totalDocsExamined: 100676,해당 쿼리 결과로 100676개의 결과가 반환되었으며 945ms가 걸렸습니다.
결과를 정리해보겠습니다.
| 10KM | 50KM | 100KM | ALL | |
| MySQL(인덱스 X) | 6775ms | 7603ms | 7785ms | 7905ms |
| MySQL(인덱스 O) | 1132ms | 3759ms | 4367ms | 6052ms |
| MongoDB | 162ms | 344ms | 362ms | 945ms |
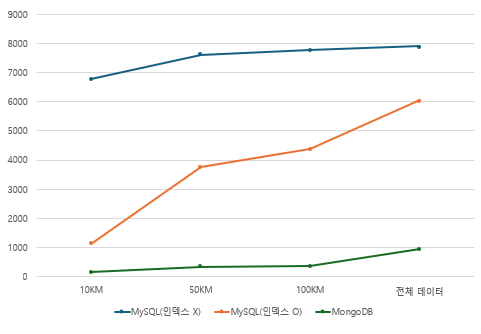
저는 이번 리팩토링을 통해서 MySQL에서 인덱스를 통해 공간 데이터 조회를 최적화하였고 프로젝트 특성상 전체 조회에 대해 서는 인덱스를 사용하지 않으므로 MongoDB를 도입하여 공간 데이터 조회에서 평균 84.34%의 성능 향상을 이루어냈습니다.
'Project > PlusKM' 카테고리의 다른 글
| [+/KM]Logback으로 EC2 환경 로그 관리하기 (3) | 2025.06.13 |
|---|---|
| [+/KM]AWS OutOfMemoryError 극복: active 컬럼 기반 공공데이터 갱신 배치 전략 (2) | 2025.06.11 |
| [+/KM]JDBC Batch로 CSV 데이터 저장 최적화 (0) | 2025.02.18 |
| [+/KM]CSV 파일 DB에 유지하기 (0) | 2025.01.21 |
| [+/KM]MySQL에서 공간 데이터 최적화하기 (0) | 2025.01.20 |



