
빙응의 공부 블로그
[JAVA]함수형 프로그래밍 - Stream API 고급 본문
📝FlatMap을 통한 중첩 구조 제거
FlatMap은 스트림의 각 요소를 다른 스트림으로 매핑한 후에 이를 단일 스트림으로 평탄화하는 데 사용된다.
즉 데이터가 2중 배열 혹은 2중 리스트로 되어있는데 1차원으로 처리해야 하는 경우 사용한다.
flatMap은 Function 함수형 인터페이스를 매개 변수로 받는다.
// 중첩된 배열
Integer[][] nestedArray = {
{1, 2, 3},
{4, 5},
{6, 7, 8}
};
// 배열을 스트림으로 평탄화하고 리스트로 변환
List<Integer> flatList = Stream.of(nestedArray)
.flatMap(Arrays::stream)
.collect(Collectors.toList());
// 중첩된 리스트
List<List<Integer>> nestedList = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5),
Arrays.asList(6, 7, 8)
);
// 리스트를 스트림으로 평탄화하고 리스트로 변환
List<Integer> flatList = nestedList.stream()
.flatMap(List::stream)
.collect(Collectors.toList());
📝Reduce를 통한 결과 생성
Reduce는 누산기(누적 계산)와 연산으로 컬렉션에 있는 값을 처리하여 더 작은 컬렉션이나 단일 값을 만드는 작업이다.
누산기와 연산이기 때문에 기존 수학적 연산이 가능하다.
list.stream()
.reduce(Integer::sum)
.get();
list.stream()
.reduce(0,(a,b)-> a+b)
.get();
이처럼 Reduce 함수는 여러 요소들을 통해 새로운 결과를 만들어낸다.
받을 수 있는 매개변수는 3개이다.
<T> T reduce(T identity, BinaryOperator<T> accumulator, BinaryOperator<T> combiner)
- identitiy : 초기값으로 사용되는 값이다.
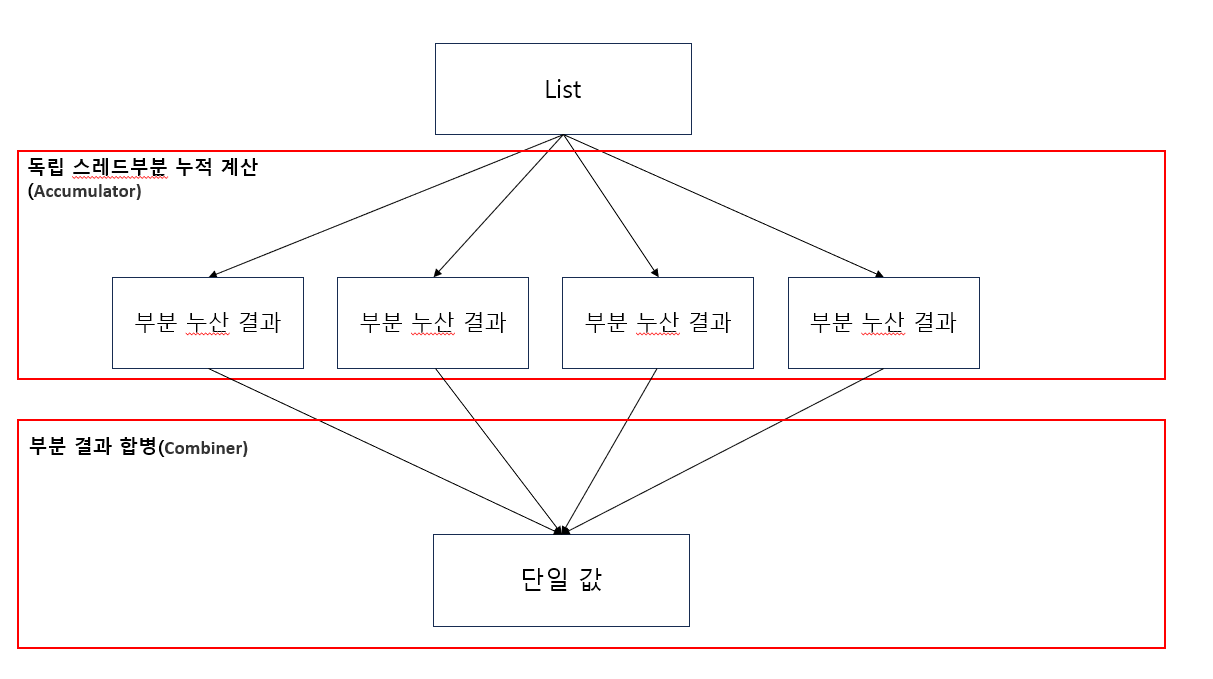
- BinaryOperator<T> accumulator : 스트림의 각 요소를 독립적으로 처리하여 부분 결과를 누적하는 역할
- BinaryOperator<T> combiner : 병렬 스트림에서 동작할 때 사용되는 파라미터이다. 즉 실행 중에 서로 다른 서브 스트림의 결과를 합칠 때 사용한다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 초기값 0을 사용하여 리스트의 모든 요소를 더함 (병렬 스트림에서는 combiner가 사용됨)
int sumParallel = numbers.parallelStream().reduce(0, (a, b) -> a + b, Integer::sum);병렬 스트림 Combiner의 이해
사실상 accumulator과 combiner는 왜 사용할까?
그것은 병렬 처리에 있다.
가장 비슷한 예로는 알고리즘의 Divide-and-Conquer 방식이다.
Divide-and-Conquer 방식은 문제를 분해해서 정렬한 뒤 합병하는 방식을 취하고 있다. Reduce도 비슷한 방식이다.
accumulator은 각 스레드가 독립적으로 작업을 수행하여 각각의 부분 결과를 누적한다.
그리고 Combiner가 누적된 부분 결과들을 최종 결과로 합치는 역할을 한다.
📝Null-Safe한 Stream 생성하기
Java를 이용해 개발을 하다보면 NPE(NullPointerException)이 매우 자주 발생한다.
물론 NPE를 방지하기 위해 Null 여부 검사 코드를 작성할 수 있지만, 기본적으로 이러한 코드는 가독성을 해친다.
이러한 문제를 해결하기 위해 Java8부터 Optional이라는 Wrapper 클래스를 제공하여 Null을 처리할 수 있게 도와주고 있다.
Stream 또한 Optional과 궁합이 좋은 편이다.
[JAVA] Optional
📝 JAVA 8 Optional 자바 옵셔널은 자바 8에서 최초로 도입 되었다. 그 이유는 바로 NULL 때문이다. 프로그래밍을 하다보면 NULL 처리를 필수적으로 하게 된다. 기존에는 NULL 체크를 해서 NULL이 아닌 경
quddnd.tistory.com
public static <T> Stream<T> collectionToStream(Collection<T> collection) {
return Optional
.ofNullable(collection)
.map(Collection::stream)
.orElseGet(Stream::empty);
} //값이 들어오면 컬렉션스트림 생성, NULL이면 빈 스트림 리턴위 코드처럼 만약 NULL 값이 들어오면 빈스트림을 만들어서 리턴한다.
스트림은 기본적으로 NULL을 허용하지 않기 때문에 Optional을 이용해 처음에 처리 해줘야 NPE에 안전하다.
빈 스트림은 요소가 없기 때문에 어떤 작업을 수행하더라도 아무런 영향이 없다.
📝Stream의 실행 순서 고려
Stream의 처리 순서는 무엇일까?
스트림의 특징은 병렬처리에 있다. 그렇기에 스트림은 각 요소를 개별적으로 처리하는 방법을 사용한다.
아래의 예를 보자
Stream.of("a", "b", "c", "d", "e")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
/*
filter: a
forEach: a
filter: b
forEach: b
filter: c
forEach: c
filter: d
forEach: d
filter: e
forEach: e
*/
우리가 평소에 보는 코드라면 절차지향 방법으로 모든 요소를 filter로 처리하고 그 반환 값을 forEach에 전달한다. 고 생각한다. 그러나 Stream은 각 요소마다 해당 스트림 연산을 순회한다.
즉, a,b,c 요소가 있을 때 a의 연산이 끝나면 b로 넘어간다.
📝Stream의 병렬 처리
Stream은 아주 많은 양의 데이터를 처리해야 하는 경우 런타임 성능을 높이기 위해 병렬 스트림을 제공하고 있다.
기본적으로 Fork-Join 즉 알고리즘의 Divide-and-conquer을 기반으로 하며 적절히 분할 후 결과를 합치는 방식을 사용한다.
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = Arrays.stream(numbers)
.parallel() // 병렬 처리 활성화
.map(i -> i * 2)
.sum();
System.out.println("Sum: " + sum);
//Reduce도 병렬 처리이다
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// reduce를 사용하여 모든 요소의 합을 계산
int sum = Arrays.stream(numbers)
.reduce(0, (acc, element) -> acc + element);
System.out.println("Sum: " + sum);
물론 위 코드와 같이 작은 데이터의 경우에는 오버헤드로 인해 오히려 성능이 떨어질 수 있다.
멀티코어 환경이나, 데이터가 큰 경우 사용하는 것을 권장한다.
✔참조 사이트
'JAVA' 카테고리의 다른 글
| [JAVA] StringBuilder (0) | 2024.07.03 |
|---|---|
| [JAVA] Buffered와 StringTokenizer (0) | 2024.07.01 |
| [JAVA]함수형 프로그래밍 - Stream API 사용법 (1) | 2023.11.30 |
| [JAVA]함수형 프로그래밍 - 람다식(Lambda Expression) (2) | 2023.11.29 |
| [JAVA]함수형 프로그래밍 - Stream API (0) | 2023.11.29 |